入料模块设计
介绍
入料模块负责物料接入,通过自动扫描、解析源码组件,产出一份符合《中后台低代码组件描述协议》的** **JSON Schema。这份 Schema 包含基础信息和属性描述信息部分,低代码引擎会基于它们在运行时自动生成一份 configure 配置,用作设置面板展示。
npm 包与仓库信息
- npm 包:@alilc/lowcode-material-parser
- 仓库:https://github.com/alibaba/lowcode-engine 下的 modules/material-parser
原理
入料模块使用动静态分析结合的方案,动态胜在真实,静态胜在细致,不过全都依赖源码中定义的属性,若未定义,或者定义错误,则无法正确入料。
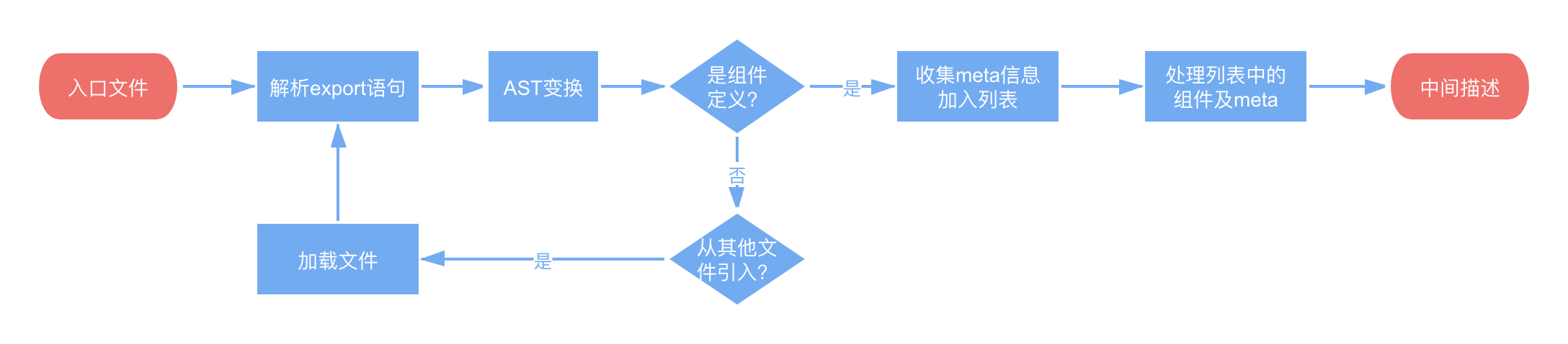
整体流程
大体分为本地化、扫描、解析、转换、校验 5 部分,如下图所示。

静态解析
在静态分析时,分为 JS 和 TS 两种情况。
静态解析 JS
在 JS 情况下,基于 react-docgen 进行扩展,自定义了 resolver 及 handler,前者用于寻找组件定义,后者用于解析 propTypes、defaultProps 等信息,整体流程图如下:
react-docgen 使用 babel 生成语法树,再使用 ast-types 进行遍历去寻找组件节点及其属性类型定义。原本的 react-docgen 只能解析单文件,且不能解析 IIFE、逗号表达式等语法结构 (一般出现在转码后的代码中)。笔者对其进行改造,使之可以递归解析多文件去查找组件定义,且能够解开 IIFE,以及对逗号表达式进行转换,以方便后续的组件解析。另外,还增加了子组件解析的功能,即类似 Button.Group = Group 这种定义。
静态解析 TS
在 TS 情况下,还要再细分为 TS 源码和 TS 编译后的代码。 TS 源码中,React 组件具有类型签名;TS 编译后的代码中,dts 文件 (如有) 包含全部的 class / interface / type 类型信息。可以从这些类型信息中获取组件属性描述。整体流程图如下:

react-docgen 内置了 TypeScript 的 babel 插件,所以也具备解析 interface 的能力,可惜能力有限,babel 只能解析 TS 代码,但没法做类型检查,类型处理是由 react-docgen 实现的,它对于 extends/implements/utility 的情况处理不好,并且没有类型推断,虽然可以对其功能进行完善,不过这种情况下,应该借助 TypeScript Compiler 的能力,而非自己造轮子。通过调研,发现市面上有 typescript-react-docgen 这个项目。它在底层依赖了 TypeScript,且产出的数据格式与 react-docgen 一致,所以我们选择基于它进行解析。
TypeScript Compiler 会递归解析某个文件中出现及引用的全部类型,当然,前提是已经定义或安装了相应的类型声明。typescript-react-docgen 会调用 TypeScript Compiler 的 API,获取每个文件输出的类型,判断其是否为 React 组件。满足下列条件之一的,会被判定为 React 组件:
- 获取其函数签名,如果只有一个入参,或者第一个入参名称为 props,会被判定为函数式组件;
- 获取其
constructor方法,如果其返回值包含 props 属性,会被判定为有状态组件。
然后,遍历组件的 props 类型,获取每个属性的类型签名字符串,比如 (a: string) => void。typescript-react-docgen 可以克服 react-docgen 解析 TypeScirpt 类型的问题,但是每个类型都以字符串的形式来呈现,不利于后续的解析。所以,笔者对其进行了扩展,递归解析每一层的属性值。此外,在函数式组件的判定上,笔者做了完善,会看函数的返回值是否为 ReactElement ,若是,才为函数式组件。
下面讲对于一些特殊情况的处理。
循环定义
TypeScript 类型可以循环定义,比如下面的 JSON 类型:
interface Json {
[x: string]: string | number | boolean | Json | JsonArray;
}
type JsonArray = Array<string | number | boolean | Json | JsonArray>;
因为低代码组件描述协议中没有引用功能,而且也不方便在界面上展示出来,所以这种循环定义无需完全解析,入料模块会在检测到循环定义的时候,把类型简化为 object 。对于特殊的类型,如 JSON,可以用相应的 Setter 来编辑。
复杂类型
TypeScript Compiler 会将合成类型的所有属性展开,比如 boolean | string,会被展开为 true | false | string,这带来了不必要的精确,我们需要的只是 boolean | string 而已。当然,对于这个例子,我们很容易把它还原回 boolean | string,然而,对于诸如 React.ButtonHTMLAttributes<any> & {'data-name': string} 这种类型,它会把 ButtonHTMLAttributes 中众多的属性和 data-name 混杂在一起,完全无法分辨,只能以展开的形式提供。这 100 多个属性,如果都放在设置面板,绝对是使用者的噩梦,所以,其结果会被简化为 object 。当然,即使没有 {'data-name': string},ButtonHTMLAttributes 也是没有单独的 Setter 的,同样会被简化为 object 。
动态解析
当一个组件,使用静态解析无法入料时,会使用动态解析。
整体流程图如下:

基本思想很简单,require 组件进来,然后读取其组件类上定义的 propTypes 和 defaultProps 属性。这里使用了 parse-prop-types 库,使用它的时候必须在组件之前引用,因为它会先对 prop-types 库进行修改,在每个 PropTypes 透出的函数上挂上类型,比如 string, number 等等,然后再去遍历。动态解析可以解析出全部的类型信息,因为 PropTypes 有可能引入依赖组件的一些类型定义,这在静态解析中很难做到,或者成本较高,而对于动态解析来说,都由运行时完成了。
技术细节
值得注意的是,有些 js 文件里还会引入 css 文件,而且从笔者了解的情况来看,这种情况在集团内部不在少数。这种组件不配合 webpack 使用,肯定会报错,但是使用 webpack 会明显拖慢速度,所以笔者采用了 sandbox 的方式,对 require 进来的类 css 文件进行 mock。这里,笔者使用了 vm2 这个库,它对 node 自带的 vm 进行了封装,可以劫持文件中的 require 方法。因为 parse-prop-types 的修改在沙箱中会失效,所以笔者也 mock 了组件中的 prop-types 库。
整体大图
把上述的静态解析和动态解析流程结合起来,可以得到以下大图。
